Below are a collection of blog posts from my time at Galois; my involvement spanned from initial idea and final writing to mentoring and overseeing others’ work.
Below is a video of my Ph. D. dissertation defense, which concerns primarily the paper Reliable Classification Explanations via Adversarial Attacks on Robust Networks, which has a pre-print available on ArXiv. In industry fields where accountability matters, it is important to have machine learning solutions which produce stable, explainable results. Through new mathematical techniques, such as a stochastic Lipschitz constraint, and designing new mechanisms for Neural Networks (NNs), such as a Half-Huber Rectified Linear Unit, I was successful in creating NNs 2.4x more resistant to adversarial examples than the previous state-of-the-art on the 1000-class ImageNet classification problem, while retaining the same accuracy on clean data with a smaller network. Explanations generated using AE possessed very discernible features, with a more obvious interpretation than prior, heatmap-based explanations. Furthermore, I demonstrated that the new adversarial examples produced by AE could be annotated and fed back into the training process, yielding improved adversarial resistance through a Human-In-The-Loop pipeline.
Working on my Ph. D. proposal and several research papers, I’ve recently come across the question of whether or not incorporating editorial feedback is a worthwhile use of time. The feedback itself is of high enough quality, but the problems uncovered through editorial feedback never feel like significant problems. Furthermore, the heuristic of editorial feedback often misses more important, structural problems within a work, that prohibit a first-time reader from grasping the relevance of that work to their interests. Instead, time for revisions might be better spent on a complete rewrite of the questionable material. I believe that aiming for a stronger narrative instead of focusing on minute details has a more significant impact on readers.
(Note that this is more of an rant/opinion piece than the other posts on this blog.)
tmux, available under most Linux distributions’ package managers and also available in OS X, is a fantastic tool not only for system administration but also for development. tmux enables long-running sessions on a machine, and plugins such as tmux continuum mean that even when the machine is restarted, the previously-running session’s scrollback buffers will be displayed so that no context as to what was happening is lost. It is much more intuitive than the classic GNU Screen, and has more features. It also boasts great support for pair programming (Ham Vocke has an excellent article on this). Following is the configuration I use as well as some justifications as to why; these exact settings were cobbled together from a host of other articles across the web.
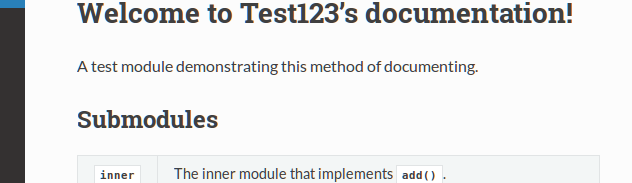
Sphinx is a great documentation tool for Python projects. The style is exceedingly legible and works well with the inline documentation style that Python exhibits. It even works great for putting together slides using reveal.js. Getting Sphinx set up for a Python module with multiple submodules, however, can be a nuisance. Most of the solutions that can be found on the internet involve creating companion .rst files for the project, which violates the convenience of Python’s inline documentation framework. This post demonstrates how to get around that for the most part, minimizing the needed amount of Sphinx markup and still producing great documentation.
git-results is a toolkit I’ve been working on for storing and organizing experiment data. In my work, I often want to tweak a script’s behavior and compare output between different invocations to understand the effects of those tweaks. The git-results extension for git provides a means for automatically logging and categorizing these different invocations, providing a memory for which changes were most effective as well as a definitive way to refer to those changes.
Cython has a number of very useful compiler directives that modify the compiler’s default behavior. These cover behaviors from enabling code profiling to changing the default python object type used to represent a C string. However, when using pyximport, the simplest way to use Cython in a project, these settings have to be configured per file or per code block, not globally. With a little ingenuity, this restriction can be overcome.
Recently, I’ve been using it inside screen, a great utility for multi-tasking remotely. Unfortunately, whenever pressing escape to leave insert vim’s mode, there is a sizeable 300ms delay during which pressing another key (such as : to enter the write command) causes a rubbish character to be inserted.
Qucs, which I wrote about in my last post, is still my tool of choice for generating nice-looking schematics. However, I have found the simulator to be lacking in a couple of ways for CMOS circuit simulation: